Computer Organization
Implementing a Processor: Multi-cycle Implementation
Andreas Moshovos
Spring 2007
MULTICYCLE
IMPLEMENTATION: The Datapath
As with the single-cycle implementation our processor will consist of two cooperating units the datapath and the control. We will first design the datapath and then the control. The key difference here is that the execution of a single instruction will take multiple cycles to complete. Accordingly, the datapath will have to change a bit.
The high-level methodology used to develop this datapath is the following: We approach instruction execution as a sequence of small steps/actions. Instead of trying to perform all these actions in one giant step/cycle we instead partition them into groups that are performed in order one after the other. Roughly the groups we will use here are:
1. Read instruction from memory.
2. Decode instruction and speculatively read two registers that the instruction might use
3. Perform ALU calculations or access memory.
4. Write result back to register file.
5. Determine next PC and update PC.
Because these steps will be executed in separate cycles it is necessary to introduce additional storage elements to remember what step of the execution we are at and to hold information as long as it might needed.
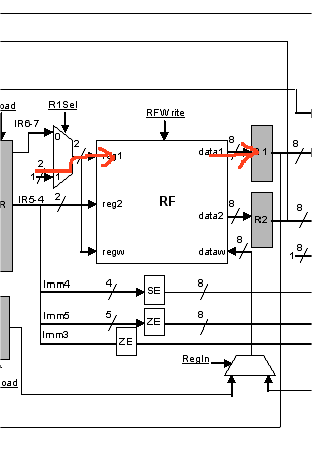
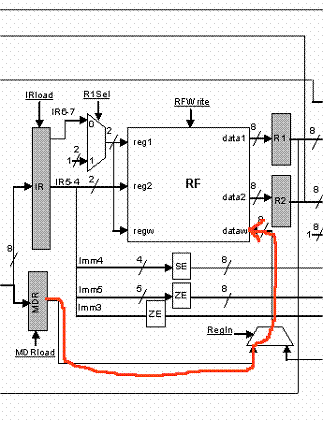
The figure that follows shows the datapath. You will notice that it is slightly different than the single cycle datapath. One key difference is the introduction of temporary registers to hold the outcomes that are produced at each cycle. For the time being please ignore the details and focus on the grey boxes. These are the new registers but keep in mind that these registers are not visible to the programmer:
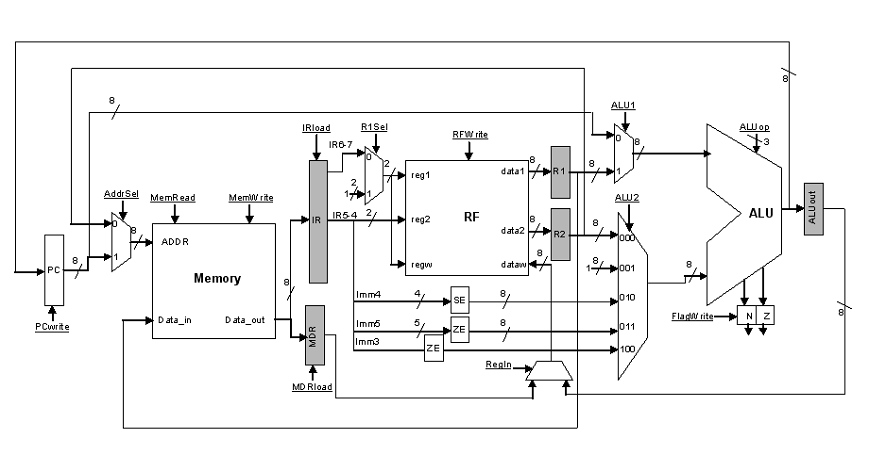
The following temporary registers are introduced:
1. IR or Instruction Register: This is used to hold the instruction encoding after it is read from memory. A register is needed because we will use a single memory device both for data and instructions. Accordingly, its output may change during the execution of an instruction (a load will read from memory).
2. R1 and R2: These are used to temporarily hold the register values read from the register file.
3. AluOut: This is used to temporarily hold the result calculated by the ALU.
4. MDR or Memory Data Register: holds the value returned from memory so that it can later be written into the register file.
Observe that in our datapath there is now a single memory device, one ALU and no additional adders. Contrary to the single cycle implementation here we do not have to replicate any functional block/unit that is used twice by an instruction. For example, we can use the same memory to read an instruction in one cycle and then read/write from/to it in a subsequent cycle for loads and stores. Similarly, we do not need to use separate adders for calculating PC + 1 and PC + 1 + SE(Imm4). We can reuse the same ALU.
Let’s see how this datapath was derived. We will explain what happens cycle by cycle. The division of work in cycles will seem arbitrary when you read the rest of the material. How one decides what can be done in a single cycle and how to partition the various actions into separate actions. This is really only possible if one knows the relative delay of each action. For example, how long it takes to read to registers from the register file, and how does this compare to performing an addition with the ALU? Ideally, we would partition the actions in a way such that every cycle is used in full to perform useful work. This means that the delay of the work performed in each cycle will be pretty much the same for all cycles. In practice, we try to get as close as possible to this ideal.
CYCLE-BY-CYCLE
DESCRIPTION
The first two cycles are the same for all instructions since we need to fetch the instruction from memory and then decode it (i.e., the control has to look at the opcode and decide what to do next).
-----
CYCLE 1: Fetching
the Instruction and Incrementing the PC
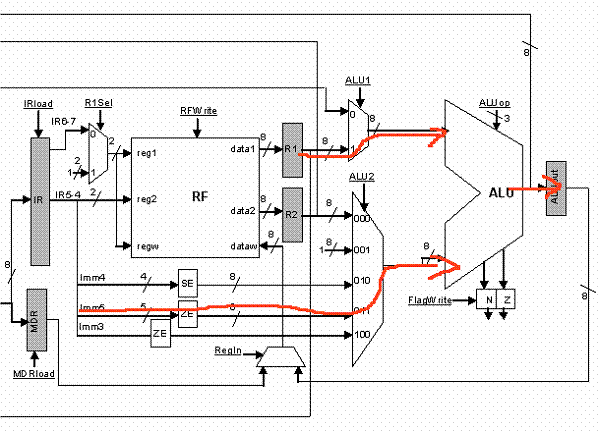
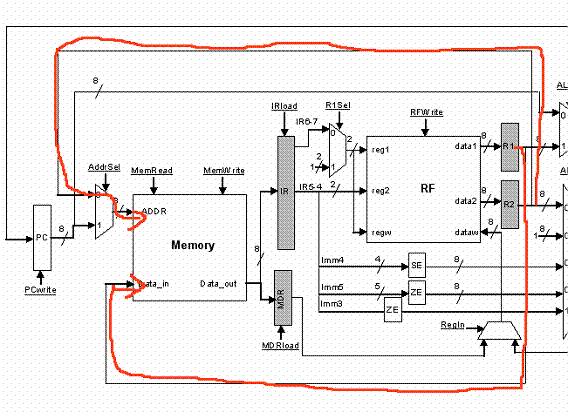
The first step in executing an instruction requires fetching the instruction from memory. For this we have to send the value of the PC register to the address lines of the memory device. Assuming that the memory will respond within this first cycle, we want to store the returned value (this is the encoding of the instruction that we should execute). To do this we need to take the value from the memory’s output and write into the IR register. These steps are possible as shown below:
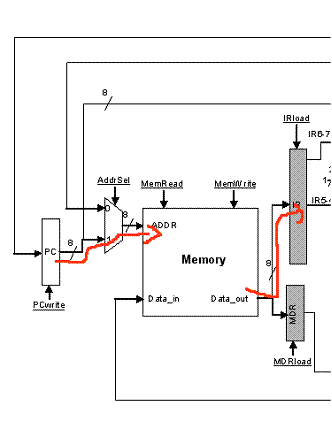
Because we may access the same memory device to perform a load or a store (read and write respectively) a MUX is needed at the address input so that it is possible to send either the PC or another address. So, during the first cycle we will be reading the instruction encoding from memory. This is probably a good time to also calculate PC = PC + 1 as all instructions use this (even branches require PC + 1 as part of their target calculation). Here’s how this is done:
In parallel with the memory access, we send the PC value through the ALU1 mux to the ALU. As the second input to the ALU we send the number 1 (input 001 of MUX ALU2). Finally, we set ALUop to 000 (addition). As a result, the ALU will calculate PC + 1. By setting PCWrite to 1, at the end of the current clock cycle (negative edge), PC will change and will become PC + 1.
CYCLE 1 SUMMARY: In summary the following actions take place during the first cycle. This is often called the FETCH cycle.
[IR] = Mem[ [PC] ]
[PC] = [PC] + 1
Note that because all instructions need to compute PC+1 it was possible to try to evaluate this as early as possible. This is one type of optimization we can apply to reduce the number of cycles needed to execute every instruction. Alternatively, we could have computed PC+1 after performing all other actions.
-------
CYCLE 2: Decoding the instruction and reading from the register file
During the second cycle, the control will be taking a look at the instruction opcode in order to decide what should happen during the next cycle. Because many instructions use the registers specified in fields R1 and R2 of the instruction we also read these registers from the register file. Note that some instructions do not use R1 or R2. In this case, we would have read registers that we do not need. While this is extra work we literally had nothing better to do during the second cycle. So, it is OK in hardware to perform actions that may be useful and later ignore the results if they are not needed. This is permissible as long as the extraneous work does not change and machine state in an irreversible way (reads do not change the register values so they are OK). In other words, reading the two registers is a speculative optimization performed at the hardware level. We guess that an action might be useful and perform it speculatively. Later on, we will determine whether this speculation is successful. In the case of reading these two registers, there is no harm when we mispeculate. We simply have read two registers. There are many other forms of speculation in modern processors, some of which require corrective action. Also note, that should we have chosen to wait to determine whether we should read the registers, those instructions that use them would require an extra cycle to execute.
It is important to note that during the seconnd cycle the datapath cannot take actions that depend on the actual instruction being executed. This is because we assume that the control needs a full cycle to decode the opcode and decide what needs to happen next. For our simple instruction set this is probably a pessimistic assumption. Not so for other architectures that have many more instructions.
Note that because the R1 and R2 field always appear at the same bit locations it is possible to blindly use them and access the register file even through the control has not yet had enough time to check the actual opcode.
Schematically, here’s what happens in the datapath:
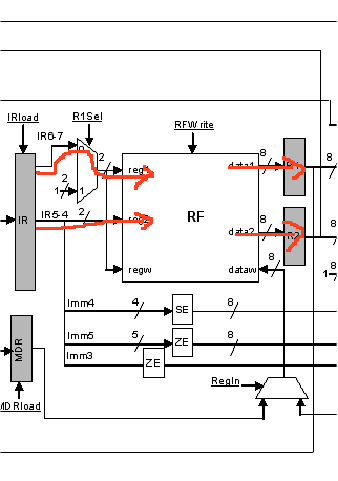
Thus at the end of the 2nd cycle, registers R1 and R2 are loaded with the values held by the registers identified by the instruction bit fields R1 and R2 respectively.
CYCLE 2 SUMMARY:
[R1] = RF[[IR7..6]]
[R2] = RF[[IR5..4]]
Instruction Decode
-----
CYCLE 3 and after
What happens after cycle 2 depends on the actual instruction. Accordingly we will consider each instruction in turn.
*** ADD, SUB and NAND
The execution of these three instruction proceeds into additional steps:
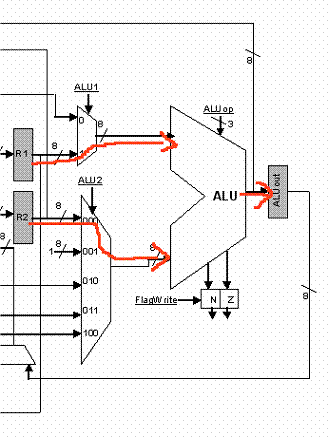
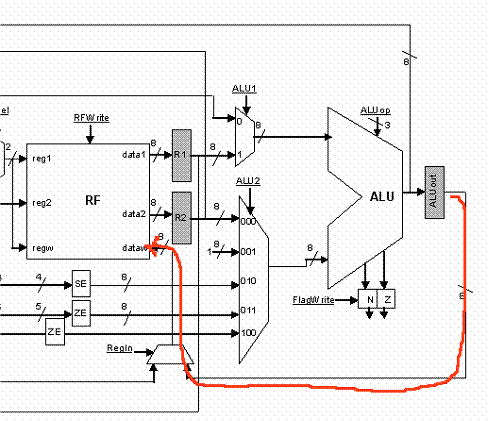
In cycle 3 we calculate the operation specified by the instruction and at the end store the result into ALUout. In cycle 4 we write the result into the register file:
|
CYCLE 3 |
CYCLE 4 |
|
|
|
*** SHIFT
Shift is almost identical to ADD, SUB and NAND. The only difference is that during cycle 3 we do not use register R2 but the Imm3 field from IR:
|
CYCLE 3 |
CYCLE 4 |
|
|
|
*** ORI
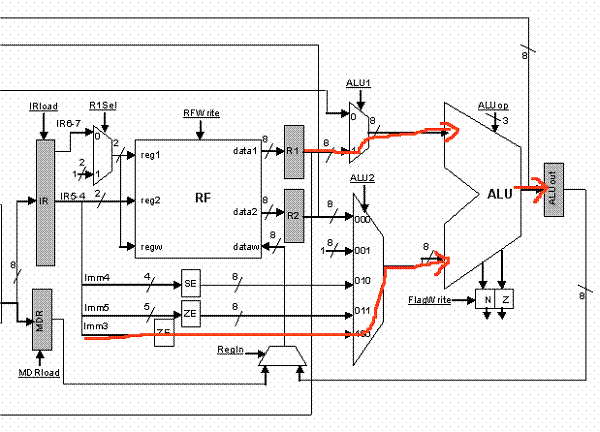
ORI uses an implied source/destination register operand. Accordingly, the register we read in cycle 2 may not be the right one. For this reason, we have to access the register file again and read K1, then in cycle 4 we can perform the OR in the ALU and in cycle 5 write the result into the register file:
|
CYCLE 3 |
CYCLE 4 |
CYCLE 5 |
|
|
|
|
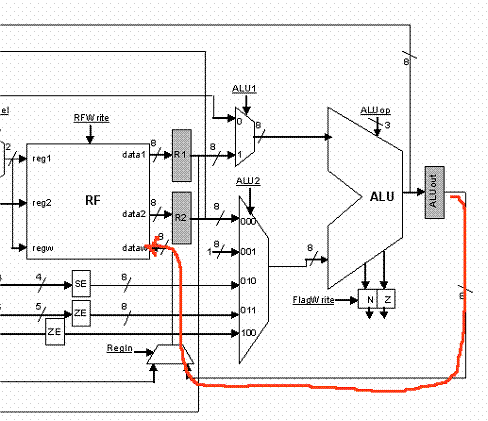
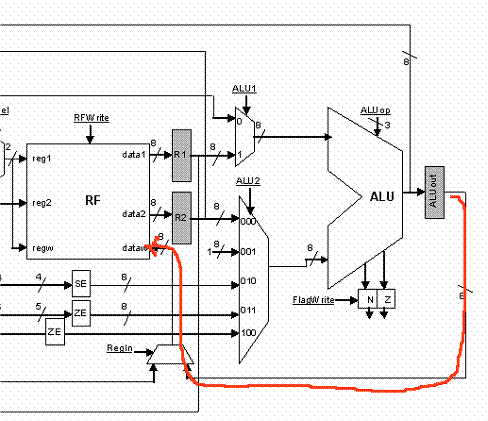
*** LOAD
For a LOAD instruction we will be accessing memory during cycle 3 and storing the returned value into MDR. Then in cycle 4 we can write this value in the register file.
|
CYCLE 3 |
CYCLE 4 |
|
|
|
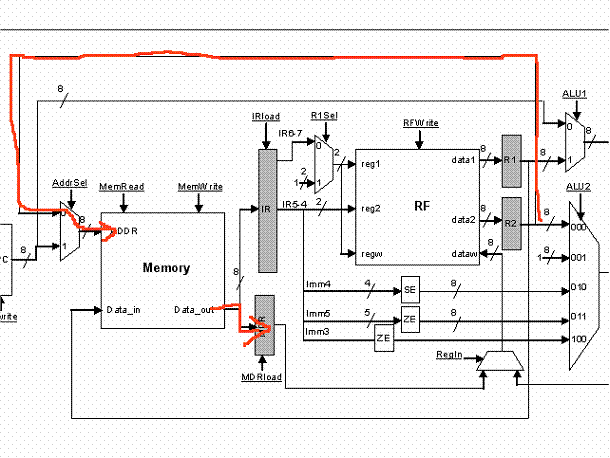
*** STORE
For a STORE instruction we will be accessing memory during cycle 3 to write the value into memory:
|
CYCLE 3 |
|
|
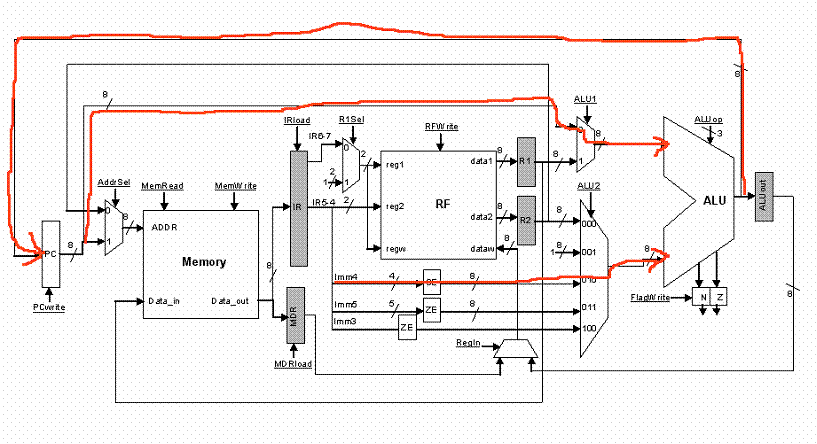
*** BRANCHES
For branch instructions in cycle 3 we will calculate PC + 1 + Sign-Extended (Imm4) and at the end of the cycle depending on whether the condition is true or not we will write this value into the PC. Recall that during cycle 1 we changed the PC to PC’ = PC + 1, so now we need to calculate PC’ + Sign-Extended(imm4):
|
CYCLE 3 |
|
|
The decision on whether to change the PC will be taken by the control. The decision can be enforced by setting the PCWrite signal (1 for changing PC 0 for keeping the PC + 1).