Lecture 19B
Phil Anderson
Spring 2005
Implementing
a One-Stage Pipeline
With our design there is a long cycle time. There is
not much time taken in the combinational logic, selects and so on, but
considerable time will be taken in any large instruction memory and in any
large data memory. During the times to fetch instructions and to fetch and
store data the rest of the circuits are not acting to decrease this delay –
they are, in a sense, idle.
Modern computers decrease the amount of idle time by
having multiple instructions go through the system at once. While one
instruction is being fetched, another is selecting register outputs which will
be used in an operation, another is using the ALU, another writing results.
Sections of the processor are isolated from each other.
This is called pipelining.
A Pentium 4 has 20 stages of pipelining. So a 4 GHz
processor is still taking at least 20 clock cycles to process any single
instruction from start to end, although (at the fastest) one instruction
finishes every clock cycle.
We will show how pipelining works by putting in one
stage of pipelining in our design. This is done by even some of the simplest
microcontrollers in the field.
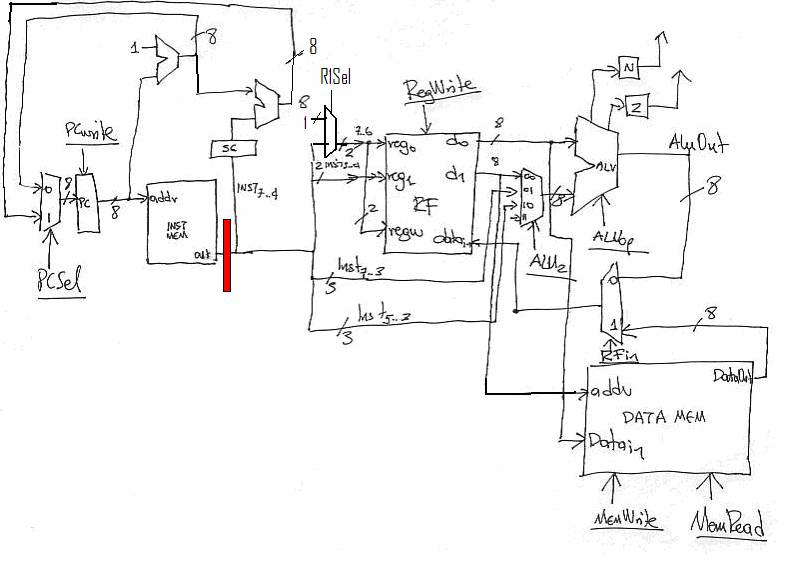
That’s it! One new latch (the one marked as red) between
the instruction fetch and the instruction execution. Let’s see what that does
for our timing.
Consider the following program –
P1 add
K0,K1
P2 sub
P3 add
K0,K3
P4 bnz
XX
P5 add
K0,K3
P6 add K0,
P7 XX sub K1,
Before, our timing for the first 3 instructions was as
follows:
|
Fetch P1 |
Execute P1 |
|
|
|
|
|
|
|
Fetch P2 |
Execute P2 |
|
|
|
|
|
|
|
Fetch P3 |
Execute P3 |
A processor cycle included a Fetch and Execute of each
instruction.
With the pipelined processor we have:
|
Fetch P1 |
Execute P1 |
|
|
|
|
Fetch P2 |
Execute P2 |
|
|
|
|
Fetch P3 |
Execute P3 |
|
|
|
|
Fetch P4 |
The processing speed has doubled (disregarding the
extra time to setup the inputs for the new latch), and we can double the clock
speed.
We have, however, one problem introduced. Let’s
consider what happens after P3 if we continue on blindly:
|
Fetch P3 |
Execute P3 |
|
|
|
|
Fetch P4 |
Execute P4 |
|
|
|
|
Fetch P5 |
Execute P5 |
The bnz statement, P4, depends on the result generated
by P3. This is not available until after we execute P3. P4 is a conditional
branch, meaning that we might be continuing on to P5 or we may be going
directly to P7 (following the branch) and skipping P5 & P6.
But our pipeline has fetched P5. If instead we want to
go to P7 we will have to skip a cycle and fetch P7:
|
Fetch P3 |
Execute P3 |
|
|
|
|
|
Fetch P4 |
Execute P4 |
|
|
|
|
|
Fetch P5 |
|
|
|
|
|
|
Fetch P7 |
Execute P7 |
There are several choices. The easiest here would seem
to be to suppress any writes in the execution stage when we decide to take a
branch. Skipping this cycle because of a pipeline problem is called a stall.
In a more sophisticated processor more aggressive
actions are taken, such as fetching both P5 and P6 after the branch,
pre-evaluating branch conditions and forcing rearrangements of instructions to
prevent stalling.
do not clock the
IR when a conditional branch instruction is fetched until the next cycle. Why?
Must wait until the address changes to get new value. Depends on N/Z which
aren’t available until the end of the last cycle.